How AI Has Changed Software Testing
From deterministic test cases to probabilistic quality judgement — a practitioner's guide to the new discipline of AI testing.
April 11, 2026

Introduction
For half a century, software testing rested on a simple premise: given a defined input, a correctly built system always returns the same output. That premise no longer holds.
AI has moved from the experimental fringes into the operational core of organisations across every sector — and the systems being built are no longer executing deterministic logic. They are making probabilistic inferences from patterns learned in data. That changes everything about how quality must be defined, measured, and defended.
This article charts how testing has genuinely changed in the AI era, through the lens of real challenges playing out in real industries. Quality assurance has not diminished in importance. It has expanded in scope, complexity, and consequence.
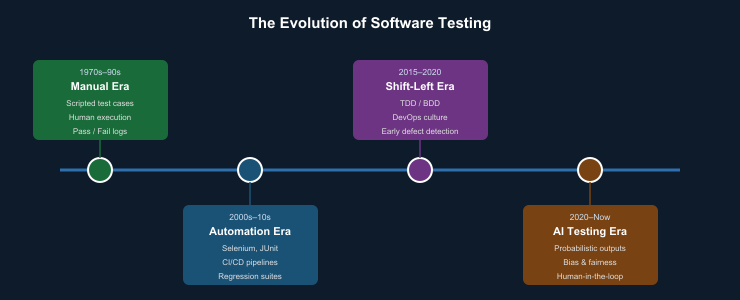
1. How We Got Here: Four Eras of Testing
To understand where testing must go, it helps to understand where it has been. The discipline has passed through four distinct eras, each shaped by the nature of the software being built and the demands placed on quality practitioners.
In the Manual Era of the 1970s through 1990s, testers executed scripted test cases by hand, comparing actual outputs against expected results written into specification documents.
The Automation Era brought Selenium, JUnit, and CI/CD pipelines. Repetitive regression checks could run continuously without human labour, freeing testers to focus on exploratory and integration testing.
The Shift-Left Era embedded testing earlier in the development lifecycle through Test-Driven Development, Behaviour-Driven Development, and DevOps culture.
The AI Testing Era, which began in earnest around 2020, breaks the mould entirely. The outputs being tested are no longer deterministic. The criteria for correctness are no longer singular.
2. What Has Actually Changed
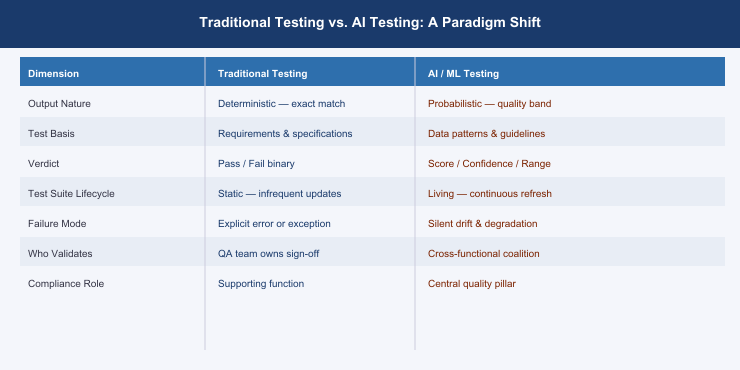
Seven dimensions of testing practice have been fundamentally altered.
- Output Nature: AI systems return outputs shaped by probability distributions, not deterministic logic.
- Test Basis: AI models are evaluated against data patterns and behavioural guidelines, not specifications.
- Verdict: Pass/Fail has given way to confidence scores, relevance bands, and fairness metrics.
- Test Suite Lifecycle: AI test datasets must be continuously refreshed as the real world evolves.
- Failure Mode: AI degradation is often silent — the model keeps responding with declining quality.
- Who Validates: AI quality requires domain experts, data scientists, legal counsel, and ethicists.
- Compliance Role: In AI, compliance is the central quality pillar.
3. Testing AI in the Real World
3.1 Healthcare: AI Diagnostic Assistance
A hospital deploys an AI model to detect early-stage lung cancer from CT scans. Training data skewed towards metropolitan hospitals with modern equipment. When deployed in regional facilities, sensitivity dropped below clinical thresholds without any error being thrown.
3.2 Finance: Credit Scoring Models
A bank replaces rules-based credit scoring with ML. The model uses postcode as a feature — which correlates with race and ethnicity, encoding historical redlining patterns. Technically accurate and legally non-compliant simultaneously.
3.3 Retail: Recommendation Engines
An e-commerce platform deploys collaborative filtering. Conversion improves 12% initially, then silently returns to baseline over six months due to model drift from pre-pandemic training data.
3.4 Manufacturing: Predictive Maintenance AI
A mining operation’s predictive maintenance model generates false positives in winter because training data was collected in warmer months. Maintenance crews begin ignoring alerts. A genuine failure is missed.

4. The New Testing Disciplines
- Bias and Fairness Testing: Systematic evaluation to detect discriminatory patterns across protected classes.
- Explainability and Transparency Testing: Assessing whether AI can articulate why it reached a conclusion. Tools like SHAP and LIME surface decision rationales.
- Robustness and Resilience Testing: Stress-testing against adversarial inputs, noisy data, and distribution shifts.
- Ethical and Safety Testing: Red-teaming exercises, jailbreak resistance, and content safety validation.
- Prompt and Response Testing: Evaluating hallucination frequency, factual accuracy, tone consistency, and refusal behaviour.
- Agentic AI Testing: Testing goal decomposition, tool selection, scope containment, and error recovery in autonomous systems.
- Evaluation-Based Testing (Evals): Structured input/output datasets scored against criteria like accuracy, groundedness, and safety.
“Traditional testing is necessary but no longer sufficient. AI demands a paradigm that blends technical rigour with ethical oversight.”
Eval-Based Testing for Generative and Agentic AI
Leading eval frameworks include:
- OpenAI Evals: Open-source framework for evaluating LLM outputs against structured task datasets.
- LLM-as-Judge: Using a capable model to score another model’s outputs on defined rubrics.
- LangSmith: Observability and eval platform for LLM pipelines and agentic workflows.
- Ragas: Framework for evaluating RAG pipelines — faithfulness, relevancy, context precision.
- DeepEval: Pytest-integrated framework with metrics for hallucination, relevancy, toxicity, and bias.
- Braintrust: Enterprise eval platform combining dataset management and experiment tracking.
- Azure AI Evaluation SDK: Microsoft’s framework covering quality and safety metrics.
- Agentic Benchmarks: GAIA, SWE-bench, WebArena, and AgentEval for multi-step real-world tasks.
5. Test Data: The Lifeline of AI Quality
In AI, the quality of test data is the quality of your AI system. Five principles govern effective test data design:
- Generalisation: Probe boundaries of learned patterns aggressively.
- Real-World Representativeness: Mirror the full diversity of production inputs.
- Bias and Fairness Coverage: Include adequate representation across all affected groups.
- Adversarial Stress Testing: Construct degraded inputs, ambiguous cases, and out-of-distribution scenarios.
- Continuous Refresh: Test data must be living assets, refreshed as the world changes.
6. Quality as a Continuous Discipline
- Model Drift Detection: Monitor statistical relationships between inputs and outputs continuously.
- Shadow Testing: Run new models in parallel on live traffic without serving outputs.
- Canary Deployments: Roll out to controlled subsets with automated quality monitoring.
- Preventing Silent Failures: Monitor output quality, not just system availability.
- Foundation Model Release Management: Baseline evaluation suites for model version changes.
- Prompt Regression Testing: Treat prompts as first-class engineering artefacts.
- Continuous Output Quality Scoring: Automated scoring using evaluator models or heuristics.
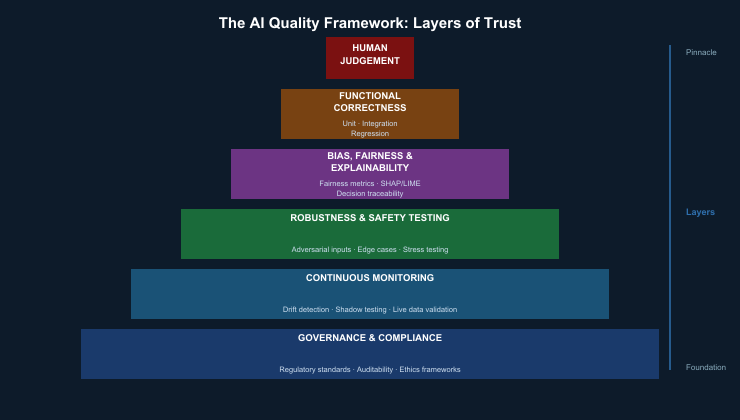
7. The AI Quality Framework
AI quality as a layered structure where each layer depends on the integrity beneath it:
- Functional Correctness: Unit, integration, and regression testing.
- Bias, Fairness and Explainability: Evaluation across protected classes with explainability tooling.
- Robustness and Safety Testing: Adversarial inputs, edge cases, distribution shift validation.
- Continuous Monitoring: Drift detection, shadow testing, automated alerting.
- Governance and Compliance: Regulatory standards, ethics frameworks, traceability.
- Human Judgement: Expert review and ethical discernment no automation can replicate.
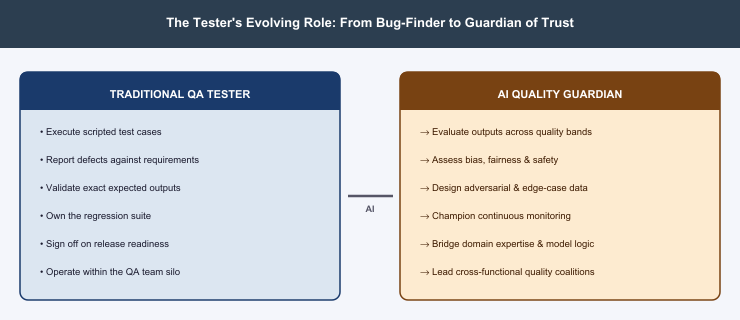
8. From Bug-Finder to Guardian of Trust
The tester’s role has not been automated away — it has been elevated:
- Quality Band Evaluation: Assessing against defined criteria of acceptability.
- Bias and Fairness Literacy: Understanding statistical fairness metrics and designing balanced datasets.
- Adversarial Thinking: Actively trying to break the model and expose blindspots.
- Monitoring and Observability: Tracking model quality in production continuously.
- Cross-Functional Collaboration: Working alongside data scientists, domain experts, and ethicists.
9. Governance: AI’s Licence to Operate
- Ethical AI Principles: Embedding fairness, transparency, and human dignity from the outset.
- Information Governance: Data integrity, lineage documentation, and lifecycle management.
- Privacy and Security: Safeguarding against inadvertent disclosure through model outputs.
- Regulatory Standards: EU AI Act, sector-specific frameworks, evidence trails for auditors.
- Auditability and Traceability: Clear records of model decisions and evaluation results.
- Adversarial Prompt Security: Red-teaming with PyRIT, Garak, and Promptfoo.
- Responsible AI Framework Testing: NIST AI RMF, ISO/IEC 42001, EU AI Act compliance.
- Trust by Design: Transparent AI disclosure, calibrated uncertainty, human escalation pathways.
“Governance is not a compliance checkbox. It is the stage on which AI earns its licence to operate.”
10. Building High-Quality Products for the Intelligence Era
- Define Quality Before Writing Code: Articulate what “good” looks like in measurable terms.
- Build Evaluation into the Architecture: Evaluation hooks at every layer.
- Version-Control Everything: Prompts, system instructions, retrieval configs, model versions.
- Design for Model Replaceability: Abstract the model layer for easy migration.
- Human-in-the-Loop Feedback at Scale: Structured mechanisms for capturing user feedback.
- Model Change Protocol: Documented process for detecting, evaluating, and approving model updates.
- Track Capability Drift: Monitor changes in what the foundation model can do.
- Safety as Non-Negotiable Baseline: The minimum entry requirement for any AI product.




